☰

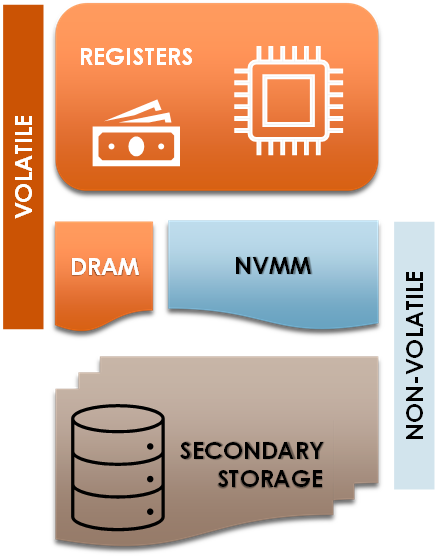
Figure 1. Memory architecture in machines with NVMs
Next generation computer systems will rely on emerging memory technologies, such as Non-Volatile Memory (NVM), to address the high computational demands of modern applications and provide persistence. Non-Volatile Memory (NVM) is solid-state byte-addressable memory which achieves better performance and higher density than the Dynamic Random-Access Memory (DRAM) on which current computers rely on. NVM technologies are expected to play a crucial role in the design of a wide range of future architectures, including not only commodity computers, but also storage servers, mobile devices, cloud systems, and the internet-of-things. PERSIST aspires to have significant impact in the following directions:
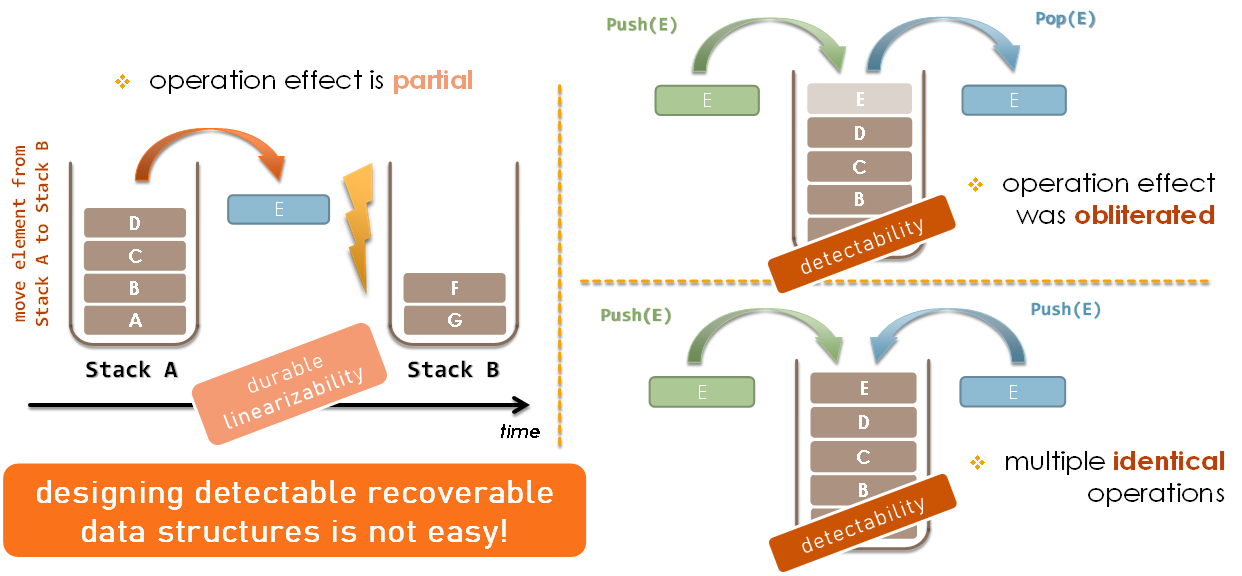
Figure 2. Challenges in designing recoverable algorithms
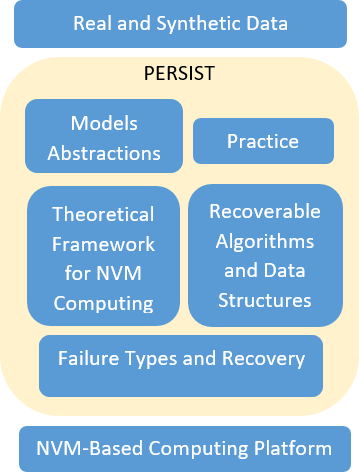
Figure 3. The architecture of PERSIST
The work to be performed in the context of PERSIST is described in Figure 3. The work will evolve around two technical work packages (WPs), namely WP2, which will build the theoretical underpinning for NVM computing to meet PERSIST’s Objective 1, and WP3, which will develop and analyze the recoverable software of PERSIT, thus addressing Objective 2. The technical WPs will be supported by WP1 (Management) and WP4 (Dissemination & Exploitation) which focus on the project management, and the dissemination and exploitation of the results.
The work of WP2 includes the following:
The work in WP3 includes the following:
C. Delporte-Gallet, P. Fatourou, H. Fauconier, E. Ruppert, "When is Recoverable Consensus Harder Than Consensus?", In Proceedings of the 41st ACM SIGACT/SIGOPS Symposium on Principles of Distributed Computing, pp. 198-208, July 2022.
We study the ability of different shared object types to solve recoverable consensus using non-volatile shared memory in a system with crashes and recoveries. In particular, we compare the difficulty of solving recoverable consensus to the difficulty of solving the standard wait-free consensus problem in a system with halting failures. We focus on the model where individual processes may crash and recover and the large class of object types that are equipped with a read operation. We characterize the readable object types that can solve recoverable consensus among a given number of processes. Using this characterization, we show that the number of processes that can solve consensus using a readable type can be larger than the number of processes that can solve recoverable consensus using that type, but only slightly larger.
Panagiota Fatourou, Eleftherios Kosmas, Themis Palpanas, George Paterakis, "FreSh: Lock-Free Index for Sequence Similarity Search", 2022, submitted.
We present FreSh, the first lock-free (thus, highly fault-tolerant) data series index that, surprisingly, exhibits the same performance as the state-of-the-art lock-based in-memory indexes. For developing FreSh, we studied in depth the design decisions of current state-of-the-art data series indexes, and the principles governing their performance. We distilled the knowledge we obtained to come up with a theoretical framework which enables the development and analysis of data series indexes in a modular way. After introducing the concept of locality-awareness, we proposed Refresh, a generic approach for supporting lock-freedom in a highly efficient way on top of any locality-aware data series algorithm. We built FreSh by repeatedly applying Refresh to make its different stages lock-free. Experiments, using several synthetic and real datasets, illustrate that FreSh, albeit lock-free, achieves performance that is as good as that of the state-of-the-art blocking in-memory data series index.
P. Fatourou, N. Kallimanis and E. Kosmas, "The Performance Power of Software Combining in Persistence", In Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2022). BEST PAPER AWARD (slides, video).
We study the performance power of software combining in designing persistent algorithms and data structures. We present Bcomb, a new blocking highly-efficient combining protocol, and built upon it to get PBcomb, a persistent version of it that performs a small number of persistence instructions and exhibits low synchronization cost. We built fundamental recoverable data structures, such as stacks and queues based on PBcomb, as well as on PWFcomb, a wait-free universal construction we present. Our experiments show that PBcomb and PWFcomb outperform by far state-of-the-art recoverable universal constructions and transactional memory systems, many of which ensure weaker consistency properties than our algorithms. We built recoverable queues and stacks, based on PBcomb and PWFcomb, and present experiments to show that they have much better performance than previous recoverable implementations of stacks and queues. We build the first recoverable implementation of a concurrent heap and present experiments to show that it has good performance when the size of the heap is not very large.
H. Attiya, O. Ben-Baruch, P. Fatourou, D. Hendler, E. Kosmas, "Detectable Recovery of Lock-Free Data Structures", In Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP 2022) (slides, video).
This paper presents the tracking approach for deriving detectably recoverable (and thus also durable) implementations of many widely-used concurrent data structures. Such data structures, satisfying detectable recovery, are appealing for emerging systems featuring byte-addressable non-volatile main memory (NVRAM), whose persistence allows to efficiently resurrect failed processes after crashes. Detectable recovery ensures that after a crash, every executed operation is able to recover and return a correct response, and that the state of the data structure is not corrupted. Info-Structure Based (ISB)-tracking amends descriptor objects used in existing lock-free helping schemes with additional fields that track an operation’s progress towards completion and persists these fields to memory in order to ensure detectable recovery. ISB-tracking avoids full-fledged logging and tracks the progress of concurrent operations in a per-process manner, thus reducing the cost of ensuring detectable recovery. We have applied ISB-tracking to derive detectably recoverable implementations of a queue, a linked list, a binary search tree, and an exchanger. Experimental results show the feasibility of the technique.
Karima Echihabi, Panagiota Fatourou, Kostas Zoumbatianos, Themis Palpanas, Houda Benbrahim. "Hercules Against Data Series Similarity Search", Proceedings of the VLDB Endowment (PVLDB) Journal, 2022.
We propose Hercules, a parallel tree-based technique for exact similarity search on massive disk-based data series collections. We present novel index construction and query answering algorithms that leverage different summarization techniques, carefully schedule costly operations, optimize memory and disk accesses, and exploit the multi-threading and SIMD capabilities of modern hardware to perform CPU-intensive calculations. We demonstrate the superiority and robustness of Hercules with an extensive experimental evaluation against state-of-the-art techniques, using many synthetic and real datasets, and query workloads of varying difficulty. The results show that Hercules performs up to one order of magnitude faster than the best competitor (which is not always the same). Moreover, Hercules is the only index that outperforms the optimized scan on all scenarios, including the hard query workloads on disk-based datasets.
Botao Peng, Panagiota Fatourou, and Themis Palpanas, " Fast Data Series Indexing for In-Memory Data", International Journal on Very Large Data Bases (VLDBJ), 2021 (a preliminary version of this work appears in Proceedings of the IEEE International Conference on Data Engineering (ICDE), Dallas, TX, USA, April 2020).
Data series similarity search is a core operation for several data series analysis applications across many different domains. However, the state-of-the-art techniques fail to deliver the time performance required for interactive exploration, or analysis of large data series collections. In this paper, we propose MESSI, the first data series index designed for in-memory operation on modern hardware. Our index takes advantage of the modern hardware parallelization opportunities (i.e., SIMD instructions, multi-socket and multi-core architectures), in order to accelerate both index construction and similarity search processing times. Moreover, it benefits from a careful design in the setup and coordination of the parallel workers and data structures, so that it maximizes its performance for in-memory operations. MESSI supports similarity search using both the Euclidean and Dynamic Time Warping (DTW) distances. Our experiments with synthetic and real datasets demonstrate that overall MESSI is up to 4x faster at index construction, and up to 11x faster at query answering than the state-of-the-art parallel approach. MESSI is the first to answer exact similarity search queries on 100GB datasets in ∼50msec (30-75msec across diverse datasets), which enables real-time, interactive data exploration on very large data series collections.
Botao Peng, Panagiota Fatourou, and Themis Palpanas, " ParIS+: Data Series Indexing on Modern Hardware", IEEE Transactions on Knowledge and Data Engineering, doi: 10.1109/TKDE.2020.2975180. https://ieeexplore.ieee.org/ abstract/document/9003246 (a preliminary version of this work appears in Proceedings of the IEEE International Conference on Big Data (BigData’18), pp. 791-800, Seattle, WA, USA, December 2018).
We present the Parallel Index for Sequences (ParIS), the first data series index that inherently takes advantage of modern hardware parallelization, and incorporate the state-of-the-art techniques in sequence indexing, in order to accelerate processing times. ParIS, which is a disk-based index, can effectively take advantage of multi-core and multi-socket architectures, in order to distribute and execute in parallel the computations needed for both index construction and query answering. Moreover, ParIS exploits the Single Instruction Multiple Data (SIMD) capabilities of modern CPUs, in order to further parallelize the execution of individual instructions inside each core. Overall, ParIS achieves very good overlap of the CPU computation with the required disk I/O.
We extend ParIS to get ParIS+, an alternative of ParIS that results in index creation that is purely I/O bounded. ParIS+ is 2.6x faster than the current state-of-the-art approach. ParIS and ParIS+ employ the same algorithmic techniques for query answering. Experiments demonstrate their effectiveness in exact query answering: they are up to 1 order of magnitude faster than the state-of-the-art index scan method, and up to 3 orders of magnitude faster than the state-of-the-art optimized serial scan.
In developing ParIS+ (and ParIS), we made careful design choices in the coordination of the compute and I/O tasks, and consequently, developed new algorithms for the construction of the index and for answering similarity search queries on this index. For query answering in particular, we studied alternative solutions, and evaluated the trade-off between execution speed and the amount of communication among the parallel worker threads, which affects the effectiveness of each individual worker.
Host Institution

Collaborating Organizations
![]()
This project has received funding from the Hellenic Foundation for Research and Innovation under the 2nd Call for H.F.R.I.'s Research Projects to Support Faculty Members & Researchers, Agreement No 03684.